How we formally verify our notification engine never sends duplicates
TL;DR
We wrote a TLA+ specification of our notification delivery pipeline and ran a model checker against it. Across every possible interleaving of concurrent workers, crashes, and provider responses, a notification is delivered at most twice. When the provider event publishing is healthy, it’s delivered at most once. The spec lives in our repo at specs/SendingEngine.tla and we re-check it whenever the design changes.
Why this matters
Five days ago we shipped a postmortem about an incident where seven customers got around 570 SMS each over four hours. Duplicate-delivery bugs under unusual interleavings are a known class of problem, and that incident hurt. So we did what AWS, MongoDB, and a handful of other infrastructure companies do for the parts of their systems they really care about. We wrote down what the system is supposed to guarantee and proved it.
Most marketing-automation platforms in our segment don’t formally verify anything. We think they should. The cost of a duplicate isn’t measured in cents. It’s measured in customer trust.
There’s a second reason this matters more for us than for most. We read directly from our customer’s database to send. No sync, no copy. That removes a whole class of “stale data” bugs but it also removes a buffer. So we put the bound in writing.
What is TLA+
TLA+ is a way to write a precise description of what a system is supposed to do, then have a computer check that no possible sequence of events can break the rules. It does not check the running code. It checks the design. If there’s some interleaving of events that breaks an invariant, the model checker hands you the exact step-by-step trace. You then either fix the design or weaken what you promised.
What we built
DF lets a business connect to its own database, define audiences with SQL, and send campaigns or run automated flows over email, SMS, and push. When it’s time to send, we pull the recipient data live from the customer’s DB, render the message, and hand it to a provider (Amazon SES for email, Twilio for SMS, FCM/APNs for push).
This post is about one piece of that pipeline. The part that takes a notifications row in our Postgres and turns it into a real external delivery.
A few things you need to know about how it runs:
- Up to 20 worker processes pull jobs in parallel from an Oban queue.
-
Each row in the
notificationstable is the source of truth for one delivery. - Workers can crash partway through a send. Networks can time out after the provider has already accepted the message. A naive cron job that tries to clean up stuck rows can cause more duplicates than it prevents.
The interesting question isn’t how the happy path works. It’s: across every possible bad interleaving, what’s the worst that can happen, and is that worst case small enough to put in a contract.
The hard part
We want to guarantee that a notification is never delivered to the same recipient twice for the same intent.
There are two specific failure modes that make this hard.
The first is what we’ll call a worker-vs-reaper race. A worker claims a row and starts calling the provider. Before it finishes, a cron-style “reaper” decides the row has been stuck too long and resets it back to pending. A second worker grabs it. Now the recipient gets two messages.
The second is the ghost send. The provider accepts the message and processes it, but the network connection drops before we hear back. We mark the row as failed. A retry sends it again.
There’s also an honest impossibility result here, which is worth saying out loud. Provider webhook events can be delayed or permanently lost. There is no way for any system to know with certainty whether a given send happened. So zero duplicates is not provable without putting a human in the loop on every ambiguous case. A small bounded duplicate rate is provable, and that’s the contract we offer. This is the same posture AWS publishes for its own services, and it’s the only honest one.
The specification
The full spec is at specs/SendingEngine.tla. It has three concurrent actors.
Workers claim rows, call the provider, and commit results. The provider event publisher eventually confirms each accepted send via a webhook, or sometimes loses the event. The reaper runs on a one-minute cron and handles rows whose worker lease has expired.
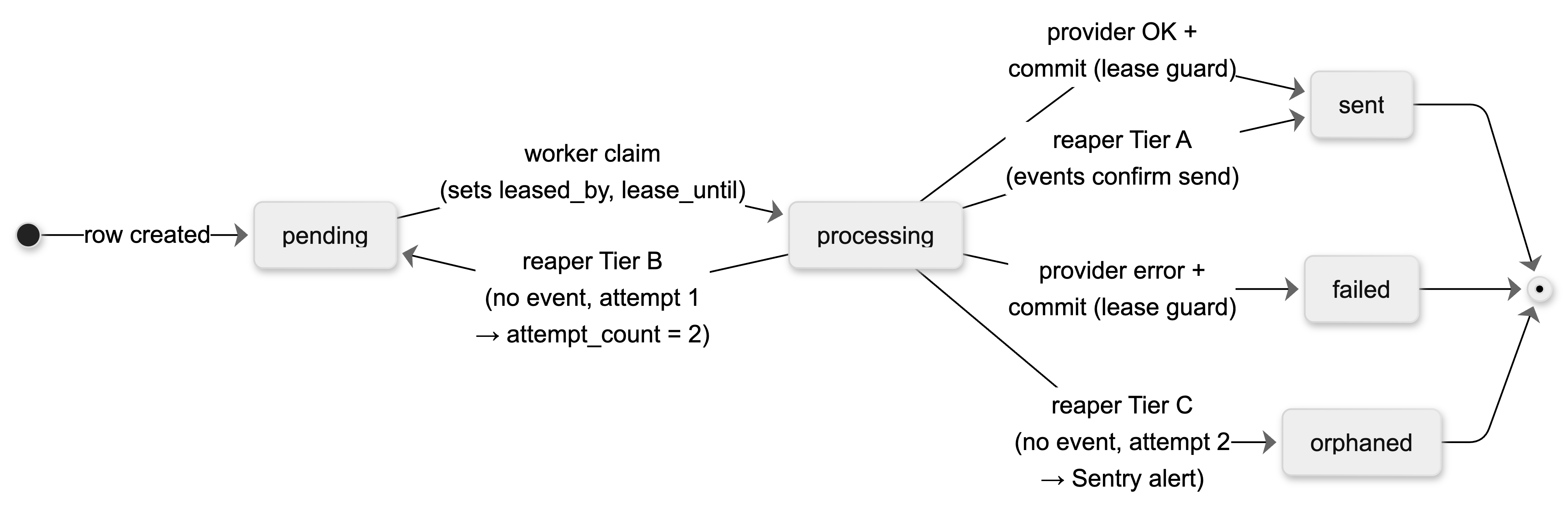
The key design idea is the lease. When a worker claims a row, it writes its own identifier into a leased_by column and sets lease_until five minutes in the future. The worker’s commit and failure paths only succeed if leased_by still matches what they wrote. So if the reaper steals the lease, the original worker’s update silently affects zero rows. The reaper, on its side, only acts on rows whose lease has expired and whose worker is no longer running.
The reaper has three tiers, in order:
- If the events table contains a Send or Delivery event for this notification, mark it as sent. No retry, no duplicate.
-
If there’s no event yet and this is the first attempt, reset the row back to pending, bump
attempt_countto 2, and re-enqueue. This is the only path where a duplicate is possible. - If there’s no event and this was already the second attempt, mark the row as orphaned (a terminal state) and fire a Sentry alert. The system never sends a third time.
The full lifecycle of a notification looks like this:
What the model checker proved
The model checker explored 207 distinct reachable states across every interleaving of two workers, the reaper, the event publisher, and worker crashes at every step. The properties we wanted, all held:
BoundedSendCount. A notification is delivered at most twice. Holds unconditionally. This is the bound we’ll put in our SLA.
SingleSendUnderHealthyEvents. If no provider event is ever lost, the notification is delivered at most once. Holds conditionally on the assumption.
OrphanedIsTerminal. A row only reaches the orphaned state after the bounded retry has actually been used. So the orphan is a true end state, not a step on the way to more sends.
EventuallyTerminal. Every row eventually settles into sent, failed, or orphaned. Nothing stalls forever.
The negative result is at least as useful as the positive ones. An earlier draft of the reaper, without the lease, violated SingleSendUnderHealthyEvents. The model checker handed us a nine-step counterexample showing exactly how a worker-vs-reaper race causes a duplicate, even when no event was lost. We fixed the design before writing the database migration.
The race the model checker found, in picture form:
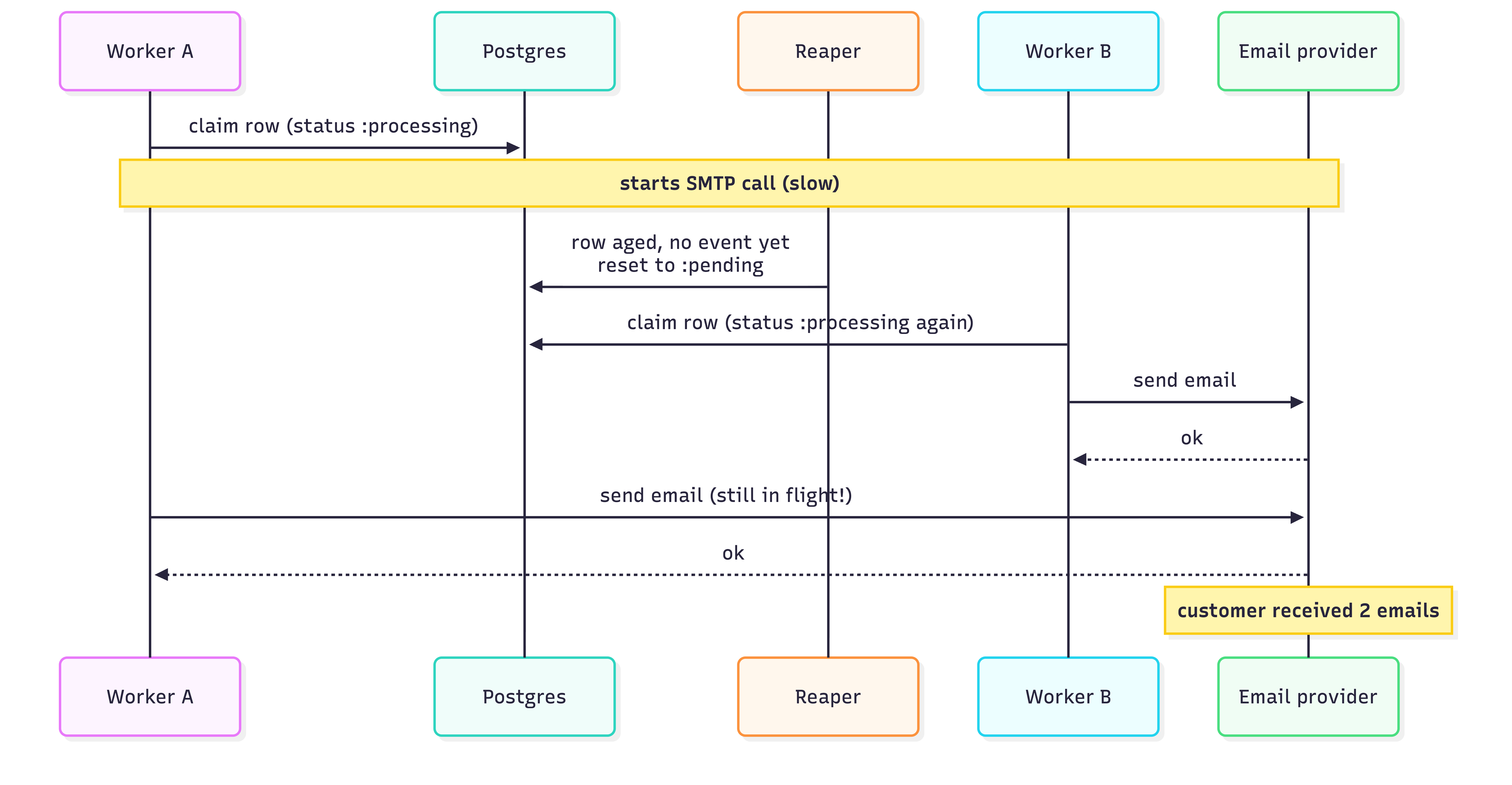
The fix is the lease. Worker A writes leased_by = "worker-A" at claim time. The reaper now refuses to act on rows whose worker is still alive, and Worker A’s commit is gated on WHERE leased_by = "worker-A", so a stolen row silently no-ops. With that change in the spec, the model checker explored 207 states and could not reproduce the duplicate.
How the spec maps to production
A spec is only useful if the design it describes is what actually got shipped. Every invariant in the spec maps to a piece of running code or a database constraint. The full mapping lives in specs/SendingEngine.md. To give one example, here’s how BoundedSendCount is enforced end to end:
The spec says notification.sent_count <= 2. The schema has attempt_count :integer, null: false, default: 1. The reaper code in notification_reaper_worker.ex has a cond that retries while attempt_count < @max_attempts and otherwise marks orphaned. The worker’s commit query in notification_sender_worker.ex is gated on WHERE leased_by = ^notification.leased_by, so a stolen lease can’t write a third send.
Code review and the tests at test/df/workers/notification_reaper_worker_test.exs close the gap between “the spec is correct” and “the code matches the spec.” That’s a gap formal methods alone can’t close.
Limitations and what we measure
The Twilio status-callback handler is not yet shipped. Today the events-found check (the first reaper tier) only finds Amazon SES events. An SMS notification that exceeds its lease always falls through to the second tier and gets retried, with possible duplicate. So SMS today has the weaker guarantee, BoundedSendCount <= 2, but not the stronger one. Closing this is the next thing we ship. Once landed, SMS gets the full guarantee. We’re flagging this here because we’d rather state it plainly than quietly hope no one notices.
The model checker proves the design. It does not prove anything probabilistic. TLA+ doesn’t model probabilities. So in production we measure orphan rate, lease-expiry rate, and SES event-arrival lag, and we alert on aggregate signals like orphan rate above 0.1% or sustained event-publishing failures. We do not alert on individual rows.
The flow engine
The second subsystem we verified is the flow engine. Flows are how customers build automated journeys: enroll a profile when something happens, send them a message, wait three days, send another one if they haven’t bought, and so on. Same correctness questions as the sender (duplicate sends, lost work) but with extra ones on top: can an admin breaking a flow mid-journey orphan customers who are partway through, can two workers race on the same enrollment, and can a profile end up enrolled twice in the same flow at the same time.
The interesting thing we discovered while writing this spec is that the flow engine needs less machinery than the sender. The sender has to invent its own dedup with a lease column, because the side effect (the call to SES or Twilio) lives outside the database. The flow engine’s side effect, creating a notification row, lives inside the same Ecto.Multi as advancing the enrollment. So the unique index on (flow_enrollment_id, flow_node_id) does the same job a lease would. Two workers race, both try to insert, the database picks one, the other rolls back. No second action ever runs.
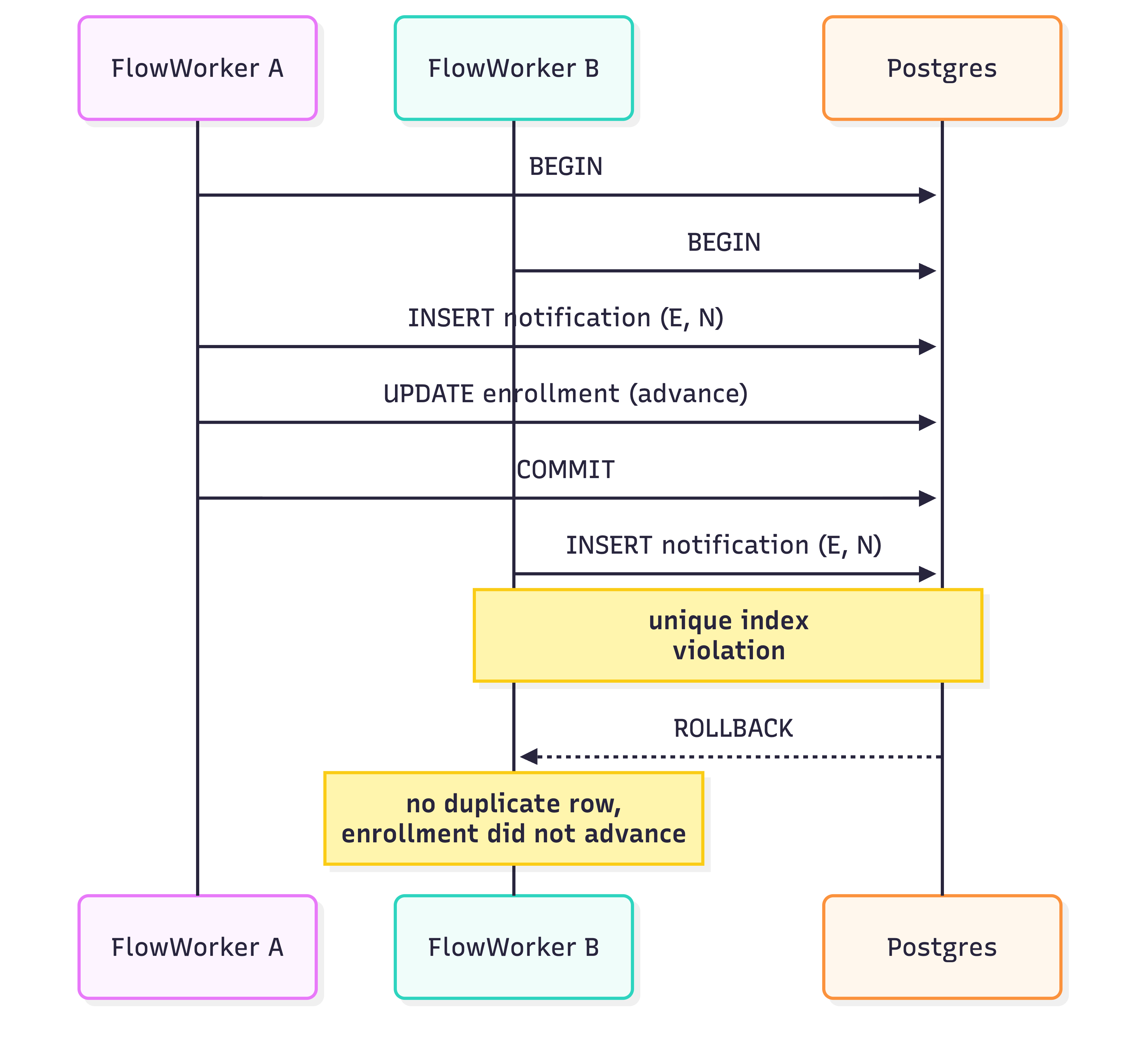
Same pattern protects enrollment creation. The unique index on (flow_id, uniqueness_key) keeps a profile from getting enrolled twice in the same flow at once. We chose to encode the recurrence policy into the uniqueness_key itself rather than using a partial index on status. So a one-time welcome flow uses uniqueness_key = hash(profile_id) and a daily check-in flow uses uniqueness_key = hash(profile_id, today). Each flow controls its own re-enrollment behavior without changing the schema.
What we proved across 856 reachable states with two concurrent triggers, two workers, and an admin flipping the flow’s active version mid-flight: at most one active enrollment per profile per flow, at most one notification per enrollment per node, and each action runs at most once. The version flip never re-enrolls a profile who is already mid-flight on the previous version.
The one gap between the verified design and the running code is small and unrelated to safety. The unique index on notifications correctly rejects duplicates, but a rejected insert raises an exception, which rolls back the enrollment advancement, which causes Oban to retry the whole job, which hits the same conflict. Loop. The fix is to use on_conflict: :nothing so the conflict becomes a silent no-op and the enrollment advances normally. This is a liveness fix, not a correctness one. Database integrity was never at risk.
The full spec lives at specs/FlowEngine.tla and the invariant-to-code mapping at specs/FlowEngine.md.
Campaigns
The third subsystem is campaigns. A campaign takes an audience that the customer defined as a SQL query, runs that query against their database, and creates one notification per recipient. Two correctness questions matter. First, that the fan-out is idempotent under retries: if the same job runs twice, no recipient gets two notifications. Second, that the A/B winner-selection logic is deterministic: when we pick which variant won the sample, we pick once and we pick the same one regardless of how the evaluator gets scheduled.
The fan-out part turned out to be already protected by infrastructure that was in place before we started this work. The notifications table has a unique partial index on uniqueness_key, which is a hash of (campaign_id, delivery_channel, recipient_uniqueness_fields). The fan-out worker creates rows with Multi.insert_all and on_conflict: :nothing, so a re-run produces zero new notifications for already-fanned-out recipients. The model checker explored every interleaving with two concurrent workers fanning out to a three-recipient audience and confirmed: each recipient appears in at most one notification, no recipients outside the audience are created, every recipient eventually gets one. We did not need to change anything. The contract is now written down.
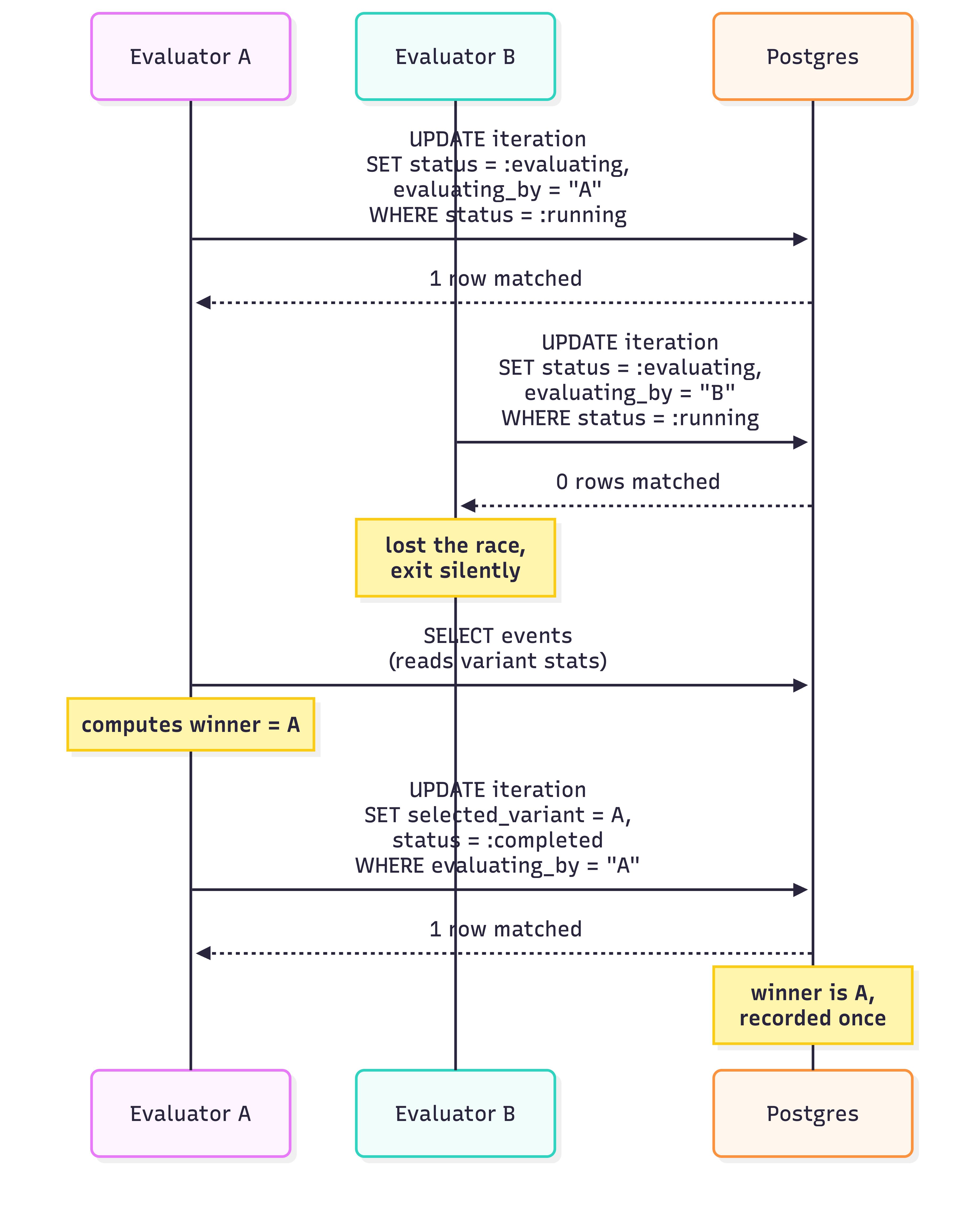
The A/B side was where we found a real race. Campaigns can run in iterations: send a sample first, evaluate which variant performed better, then roll out to the rest of the audience with only the winner. The evaluator is an Oban job. The audit found that two evaluator jobs can fire against the same iteration, both compute a winner against possibly-different data snapshots (a few new opens or clicks arrive between the two reads), and both write selected_variant_id. Last write wins. The recorded winner could disagree with the variant that drove the auto-rollout, depending on which job got there first.
The fix is the same lease pattern we used for the sender, applied to a single mutable row. The evaluator first runs an atomic UPDATE that transitions status = :running to status = :evaluating and stamps evaluating_by = $worker_id. The losing evaluator’s UPDATE matches zero rows and exits silently. The commit that records the winner is gated on WHERE evaluating_by = $worker_id, so a delayed evaluator whose lease was stolen also matches zero rows. We proved this across 34 states with two evaluators racing on a two-variant iteration: the winner is recorded at most once, status only moves forward, the recorded winner is always one of the offered variants.
We deliberately did not verify three other A/B properties. Variant assignment per recipient is a hash function, so it is deterministic by construction; same recipient always picks the same variant. The split of the audience between sample and remaining uses the same hash with a different salt, so the two sets are complementary by construction. The convergence of the actual traffic split to the declared percentages is probabilistic, and TLA+ does not model probability. These three are documented as “considered, intentionally not specified” in specs/CampaignIteration.md so a future engineer knows the work was thought through.
The fan-out spec lives at specs/Campaign.tla. The iteration evaluator at specs/CampaignIteration.tla. The one code gap left is the claim mechanism in IterationEvaluatorWorker, which closes the race the spec is verifying against.
What’s next
The remaining piece is the wait_delay node. When a flow tells a customer to wait three days, an Oban scheduled job is what brings the enrollment back to life. Oban can fire that scheduled job twice under clock skew or under retry, which is a different race than the worker concurrency we already covered. Smaller spec, focused on resumption.
We will keep adding sections to this post as each piece lands. The intent is for this to grow into one paper covering DF end to end.
References
- Newcombe et al., “How Amazon Web Services Uses Formal Methods,” Communications of the ACM, April 2015.
- Hillel Wayne, Practical TLA+. Apress, 2018.
- learntla.com.
-
specs/SendingEngine.tla,specs/SendingEngine.md,specs/FlowEngine.tla,specs/FlowEngine.mdin our repository.